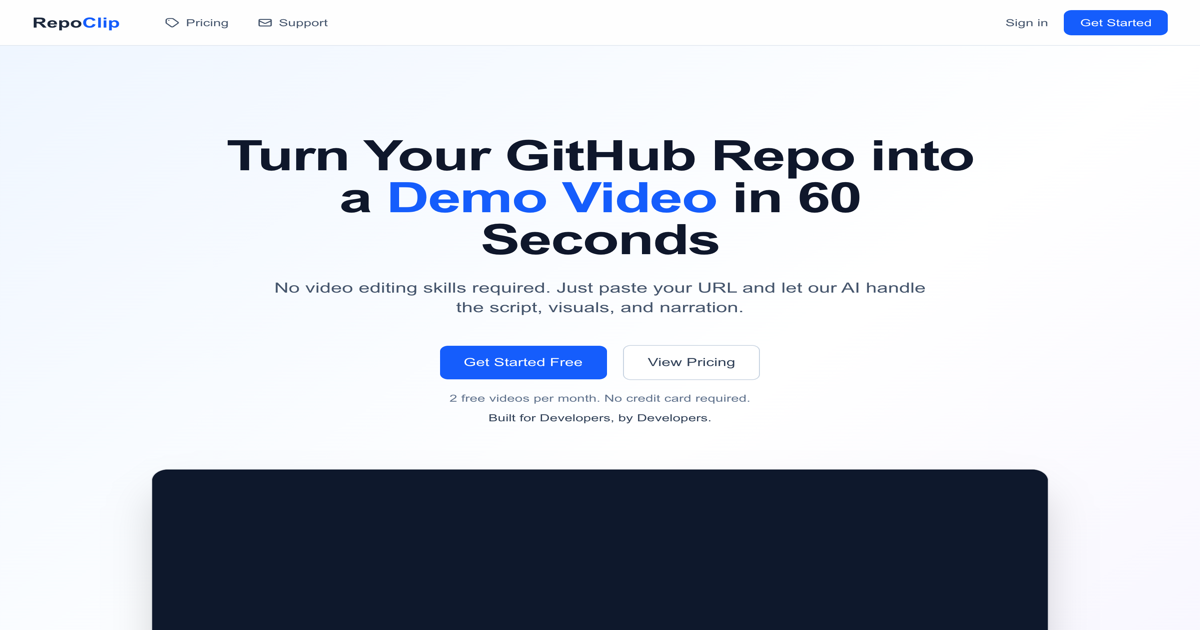
Save tokens and extend your coding sessions. CtxSift is aimed at indie founders, solo builders, and small teams working in artificial intelligence who need a focused tool without enterprise overhead.
What CtxSift does
CtxSift focuses on artificial intelligence use cases described in its listing: Save tokens and extend your coding sessions Founders typically use tools in this category to reduce manual work and ship faster with limited resources.
Who CtxSift is for
CtxSift is a fit for indie founders and small teams actively working in artificial intelligence. It is less relevant if you are not solving that problem yet or already have an entrenched enterprise stack.
Pricing & access
CtxSift uses a free pricing model. Founders evaluating artificial intelligence tools should weigh cost against workflow fit, not just feature breadth.
Key features
- Save tokens and extend your coding sessions.
- CtxSift is aimed at indie founders, solo builders, and small teams working in artificial intelligence who need a focused tool without enterprise overhead.
- What CtxSift does CtxSift focuses on artificial intelligence use cases described in its listing: Save tokens and extend your coding sessions Founders typically use tools in this category to reduce manual work and ship faster with limited resources.
- Who CtxSift is for CtxSift is a fit for indie founders and small teams actively working in artificial intelligence.
- It is less relevant if you are not solving that problem yet or already have an entrenched enterprise stack.
- Pricing & access CtxSift uses a free pricing model.
Explore more artificial intelligence tools on IndieHunt.